About Me
Hi! Thanks for visiting my site. Here you'll find a few projects I've worked on recently. I particularly enjoy working on projects that involve all parts of the data science stack. From data collection to modeling to software engineering/web-development. Right now, I'm a Master's of Data Science student at the University of San Francisco. I'm also a current Data Scientist at Accountability Counsel, a human rights non-profit. I create web-scraping tools and build document search capabilities, in order to better track global human rights complaints. My background is in data analytics and visualization, building business intelligence platforms. Always keen to discuss data science or collaborate on new projects, reach out!
Projects
Click the icon links for the project website and/or code repo.

When I was training for my first triathlon, I had no previous experience swimming competitively. But, I wanted to know what kind of time I should be aiming for! So I was curious: could I build a machine learning model to predict a swim time based on my age, gender, and expected bike/run times? The resulting project involved scraping the web for Olympic distance triathlon race results, building a model, and deploying it on AWS.

As part of my research fellowship with Accountability Counsel, I gave a presentation on the work I did building data-driven tools to help users track human-rights cases affected by global development projects. The audience are members of the Schmidt Family Foundation, University of San Francisco Data Institute, and general data science community.


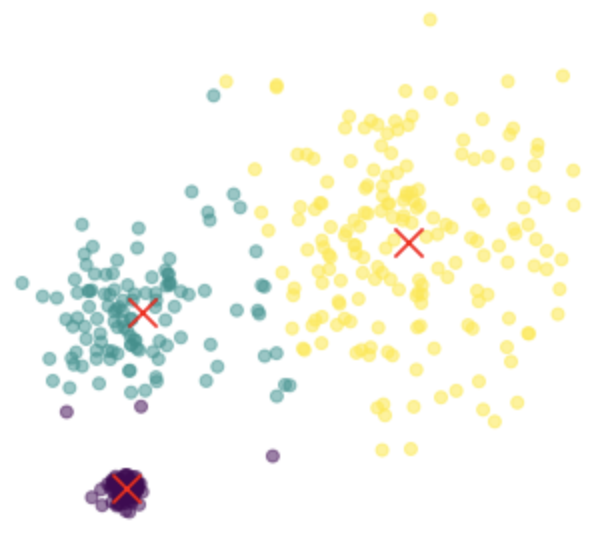
Using data on Homebrewed Beer Recipe data, the style of each beer is predicted based on physical characteristic of the recipe (ABV, IBUs, etc.). This is a classification problem with a high number of classes, and a variety of different models are used to predict the style of beer (logistic regression, kNN, RandomForests). Model and pipelines built using Scikit Learn.